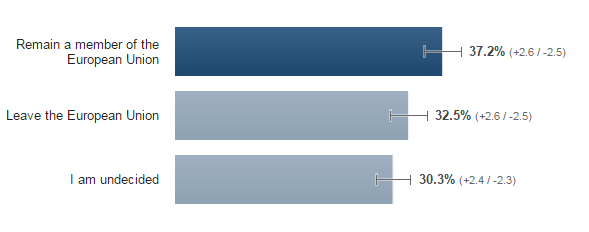
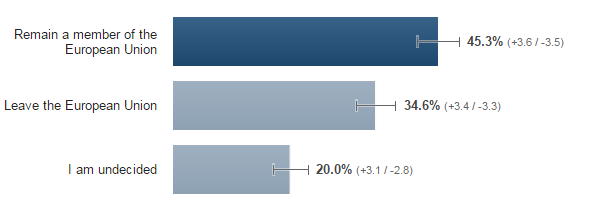
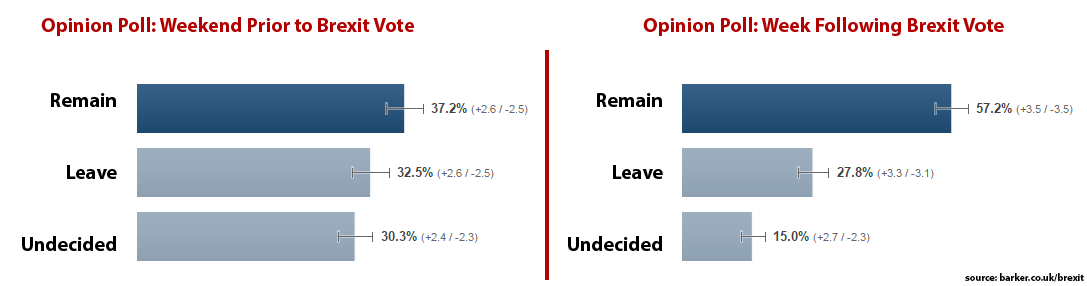
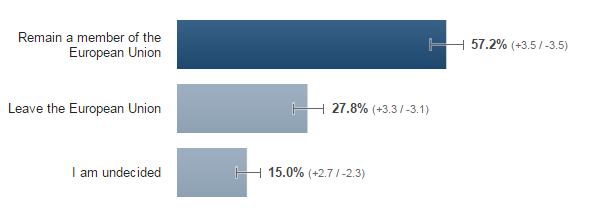
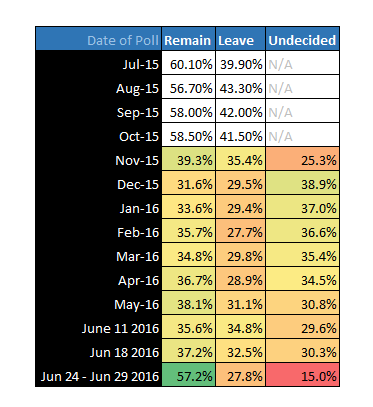
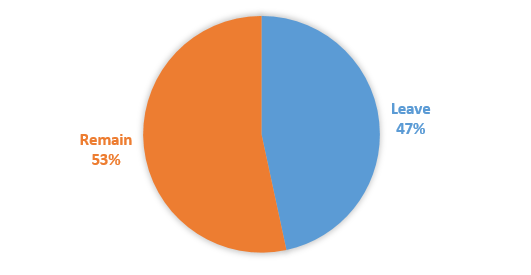
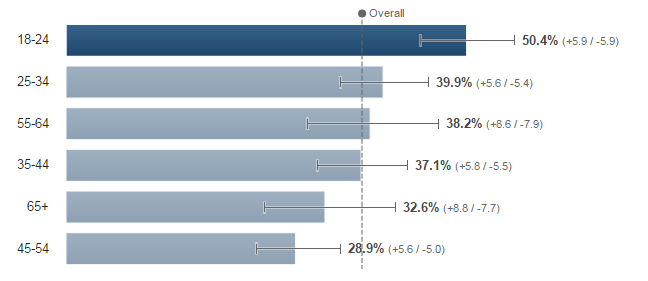
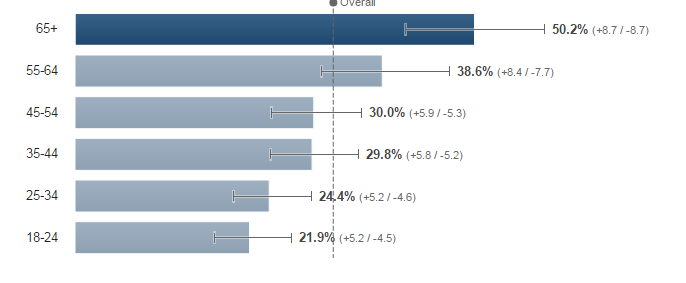
There have been lots of articles over the last week or so talking about “fake news” on Facebook, many revolving around the US election.
The ‘poster child’ of Facebook Fake News is this post: “FBI Agent Suspected in Hillary Email Leaks Found Dead…“. It appeared a few days before the US presidential election, and was shared a phenomenal number of times (567,752 according to Facebook’s API). It turned out the “Denver Guardian” does not actually exist – the site is just a shell set up to spread fake news, registered under an anonymous domain owner.
Here’s a quote from an article debunking it:

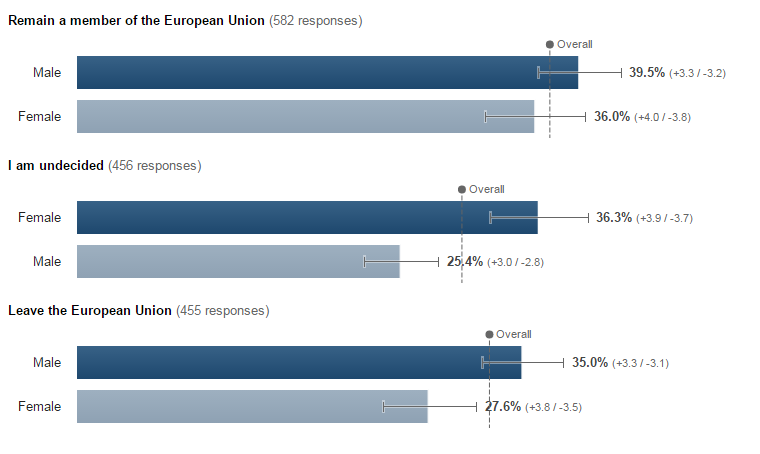
Interesting, eh? So the fake Denver Guardian article was “several orders of magnitude more popular a story than anything any major city paper publishes on a daily basis”. And here’s a graph from that article, backing that up:
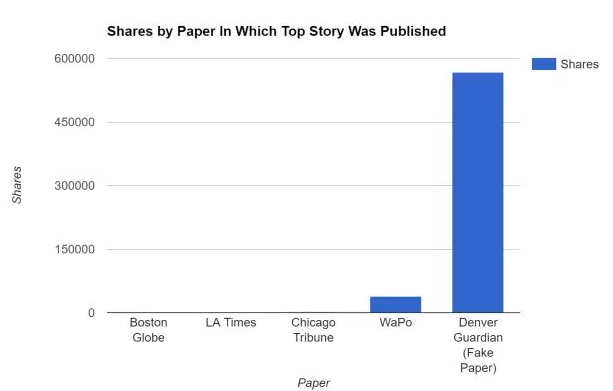
Quite a compelling chart. From that graph it looks like that Denver Guardian article is way way way more popular than anything the Boston Globe, LA Times, Chicago Tribune, and others have ever posted. Here you can see that debunking article shared on Twitter – Benedict Evans of the famous VC firm Andreessen Horowitz is retweeing it here, on an original tweet from Jay Rosen, who’s a Professor of Journalism at NYU:
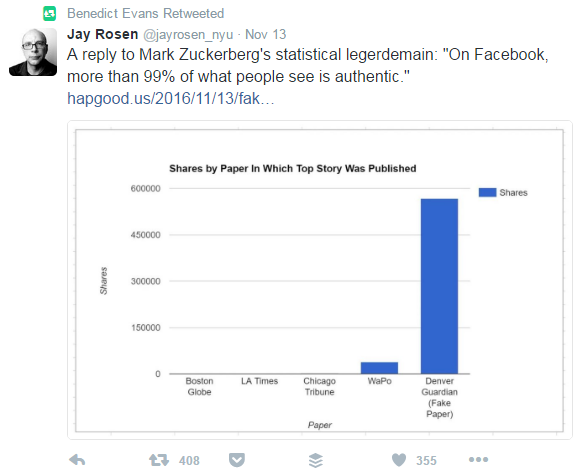
408 retweets – I bet quite a few people read that post . Except… if you read into the detail properly, and check the actual data… that graph is not representative either. Here is why:
- The author of the article just picked a single post, listed as ‘top story’, from each of the publications listed above, on a single day. If he’d picked a day earlier at a different time, he’d have found much more popular articles; if he’d picked a day later he may have too.
- That line about “this article from a fake local paper was shared one thousand times more than material from real local papers” – strictly speaking that’s true, because “material” could mean any article. But it provides a false impression.
I spent a few minutes looking for the actual most shared posts on each of the above listed websites to remake the graph taking the actual ‘most shared’ posts. I went back to the start of September 2016. Here’s how the amended graph looks:
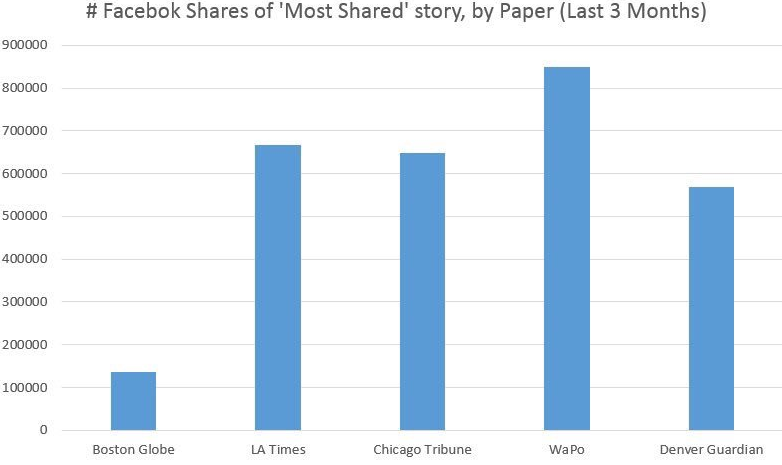
The “Denver Guardian” post is still very high there, but it’s not “several orders of magnitude more popular a story than anything any major city paper publishes on a daily basis”.
In other words: An article debunking fake news on Facebook actually gives a very false impression of reality itself. It was compelling enough that an NYU professor shared it, & several hundred people retweeted that. The article has itself been shared more than 1,500 times on Facebook.
The author was told that the article was wrong. He quietly updated some of it, and added an explicit update note to the end later on, but most of the elements in the post are left as-is. It still says the Denver Guardian’s article is “several orders of magnitude more popular a story than anything any major city paper publishes on a daily basis”, and the graph remains in tact. The NYU professor was told too, but left the RT as-is. Both probably did all of this with good intent, but the result is some who read it may take it at face value, and believe the problem to be “several orders of magnitude” greater than it likely is.
Summary:
- Yes, there is fake information on Facebook. Some of it is deliberate; some of it is due to simple incompetence.
- If you pick the most shared ‘fake news’ article of all time on Facebook, and compare it against some moderately shared posts from reputable news outlets, the outcome is that the problem looks much greater than it may be.
- Sometimes very reputable people accidentally share false information; sometimes they leave it there even after it’s noted as being not quite right.
- Fake news is still a problem. If you wanted, you could probably cheat the stock market, or nudge one or two votes in an election, by timing & pushing a piece of fake news at the right time. And, realistically, there are plenty of avenues Facebook could explore to limit the effectiveness of ‘fake news’.
Take what you read with a pinch of salt and, where you have a few moments spare, do a little of your own research to double check its validity. If it does not “pass the smell test”, maybe wait before hitting RT. But don’t overreact to the problem… it’s extremely unlikely that this fake news is “several orders of magnitude more popular a story than anything any major city paper publishes on a daily basis”.