Lots of the newspaper articles about Cambridge Analytica speak as if what they (apparently) did was extremely advanced. Many also speak about it as if it’s unrepeatable.
It was not extremely advanced. And it is repeatable.
- Advanced? Most of the things they apparently did were standard marketing tactics stretched in an unethical way.
- Repeatable? In order to repeat what they did: All you would need is money, knowledge, & some moderate data skill (moderate may be read as ‘talented year 1 university computer science’ level; more is better, but with the right knowledge & setup, what they did doesn’t seem to be a task of extreme skill).
Below is an example detailing at a high level how someone could repeat what they did today.
Important caveats:
- This doesn’t take into account legality, though all of the tools mentioned are widely available (+data laws change frequently).
- This doesn’t take into account ethics. Some of those who’ve come forward from Cambridge Analytica have essentially said “I was just doing my job” – I think if you are working to alter people’s behaviour, you should be ethically aligned with what you’re doing (or at least not fully opposed).
- It’s important also to note that Cambridge Analytica say they did nothing wrong, and that the data they used was gathered legitimately. That may well be the case: It would not be hard to do what they appear to have done by gathering the data legitimately, just more costly.
I’ve split this into 3 parts: ‘The Data’, ‘Taking Action’, ‘Summary’.
Section A: The Data
Data Step 1. Gather Personality Type Data
One of Cambridge Analytica’s big ‘Unique Selling Point’ claims was that they used ‘Psychographic Targeting’ to influence potential voters. This has a fancy name, but is a fairly simple principle, and is used within some mainstream marketing activity (mainly mass advertising, or data work designed to understand user behaviour).
Psychographic Targeting basically means categorising users into different personality types, and presenting them with different information or different ads designed to appeal to the flaws/nuances of their personality in order to push them toward carrying out particular behaviours. In the case of Cambridge Analytica, they say they did this either to urge users to vote, to move users toward ‘advocacy’ (pushing others to vote), or to suppress the likelihood of some voting for an opponent.
We know Cambridge Analytica claimed Psychographic Targeting as a big part of what they did, as the CEO (Alexander Nix) liked to do presentations telling people they did:
(from: https://www.youtube.com/watch?v=n8Dd5aVXLCc)
In part, this may be sales pitch: Anyone who has worked with high-spend media agencies knows they occasionally embelish the truth a little saying they’re using advanced techniques. Here though it looks like they did carry out some of this activity:
Below a slide where you can see him showing data including what’s referred to as ‘Big Five Inventory’. That means targets categorised by the ‘Big 5’ personality traits: Openness, Conscientiousness, Extraversion, Agreeableness, Neuroticism (‘OCEAN’).
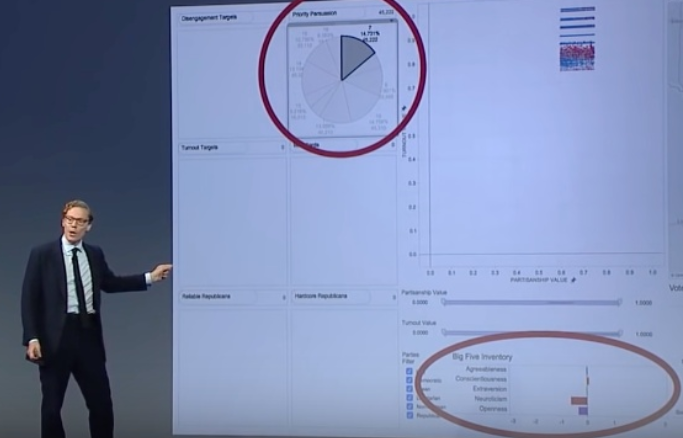
(snipped from: https://www.slideshare.net/GMline/the-power-of-big-data-and-psychographics-in-the-electoral-process)
Whether or not you believe this stuff works to the extent they say it did aside: This is probably the hardest element in replicating what Cambridge Analytica did, as it requires a big base of personality data. That’s essentially what they (Cambridge Analytica) & Facebook are in trouble for: The claim is that they used dodgy methods to acquire that personality data, and did not delete that data when Facebook asked them to.
Gathering a Pool of Personality Data
There are many ways to gather personality type data. If you wanted to replicate what Cambridge Analytica did, and you had the money, you could simply buy up a legitimate source of personality data.
There are many companies that collect this kind of thing. Some are very small operations sitting on lots of data, and therefore likely to be ‘cheap’ to acquire. Here’s one example, who use ads on The Guardian and many other publications to bring new customers to their IQ and general Personality Tests:
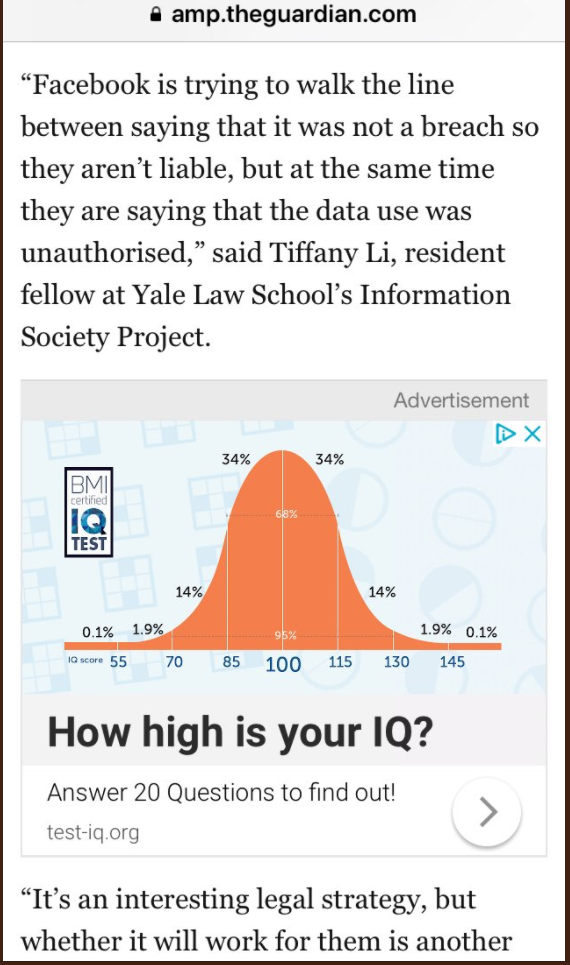
(Ironically the above is from a Guardian article on Cambridge Analytica)
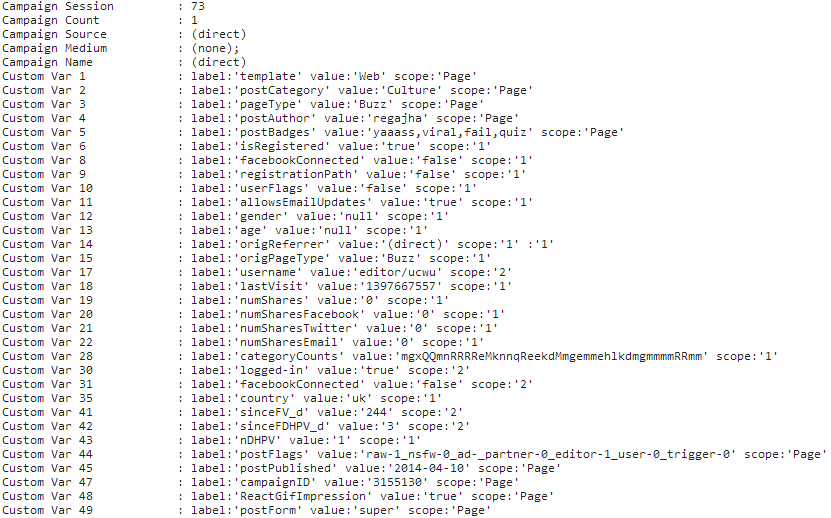
To get an idea of the amount of data those people hold, below are some rough monthly estimates of the traffic for the site listed in the ad there (the stats below are gathered from another tool that monitors’ users behaviour – SimilarWeb – who buy up data on millions of web users’ habits):
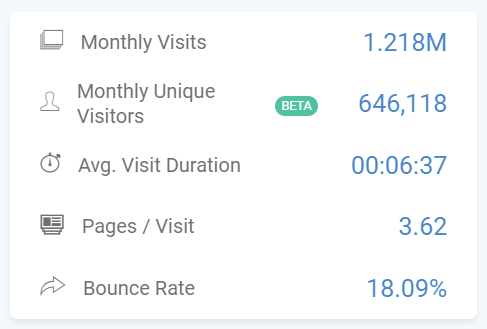
From either creating a set of personality data yourself, or acquiring it via a third party source (either buying from a company that has it or buying a company outright that has that type of data) you could be then fairly simply categorise users within that data, allowing you to A) test the effectiveness of ads by personality type, B) use that data & that feedback loop to tailor messages for other channels.
Personality Data Summary: It should be quite straightforward to buy a big source of personality data. If you need to grow one from scratch, you can still do that legitimately using ads to send people to personality tests (ironically, The Guardian host lots of those ads at present).
Data Step 2. Add to your Personality pool with a broader data set.
Your pool of personality type data could be used to segment some users. An extra claim re Cambridge Analytica is that they also linked this to a wider set of data (In their case: all the Facebook contacts of users who took personality tests). They appear to have had various information on those users – age, gender, location, relationship to other users within their pool, and more.
2.1: Buying a set of data.
You could replicate that, but Facebook have tightened up their controls since. The data could, however, be gathered in different ways: There are many vendors of Email Data. Sometimes this data comes with the permission to email users, sometimes it does not. Sometimes it comes with many of the above attributes (age, gender, location, etc).
Summary: Many companies sell data on US / UK / citizens of other countries.
2.2: Adding to that set of data.
There are also many, many services who allow you to ‘augment’ email data. Some of these simply provide age, gender, whether the email address is active or not. Some provide much more in depth categorisation. Here are 3 examples who provide much more:
- FullContact lets you supply a list of email addresses & returns with details from their accessible social media profiles (including profiling of bands, books, topics users have mentioned, etc).
- Clearbit does something very similar, collecting ‘data from over 150 sources in real time’.
- Pipl is another tool, with data on over 3,163,959,452 people, allowing you to gather details of their social media profiles, job information, and more.
Here’s a snapshot of some of the data available from FullContact, provided matched against a list of email addresses you provide to their system:

Using some of the above sources, it may also be possible to carry out the ‘social graph’ analysis that Cambridge Analytica’s set of data appears to have allowed them (ie, which users are connected to which others; which are of particular influence, etc).
2.3: Further data sources.
Each of the above are quite legitimate data sources (albeit having ‘permission’ to contact them relies on that having already been granted & documented somewhere). Alongside each of the above, there are many less legitimate sources of data available. Two examples of this type of data :
- Data gathered by browser plugins. Many users don’t realise, but the plugins you add to web browsers can often record which sites you visit, when you visit them, other activity in the browser (text you put into some forms, etc).
- Data gathered by mobile apps. For example: Those ‘Free Flashlight’ apps on your phone? How do you think they make money? Some mobile apps record what you do on your phone, which other apps you use, where you go, which websites you visit, your contacts, and more.
Each of the above could be used
There are many other sources of data like this, from big credit reference agencies, to small operations who buy up email data.
Data Step 3. Link any data you’ve sourced with data gathered directly yourself
Every political campaign gathers their own data, and uses this to understand which voters to target as ‘voters’, which as ‘advocates’ (ie. those who will push others to vote – sometimes creating lists of those people individually so that campaigners can ring round on the day to ensure everyone’s voted), some may also identify opposition voters to attempt to ‘suppress’.
The official UK Brexit campaign built a system like this called ‘VICS’ the ‘Voter Intention Collection System’. Many use off-the-shelf tools.
One such off-the-shelf tool is ‘Nation Builder’ – which allows anyone with money to build up big databases of their own supporters. Nation Builder has been used by almost every political organisation you can think of (plus charities and others). It was used by the UK ‘Remain’ Brexit campaign, as well as by UKIP (the UK Independence Party). It was used by Donald Trump and it was used by Bernie Sanders. It was used by Ted Cruz, even though it was created by a former John Kerry aid. It’s used by the Conservative Party in the UK, and also used by the Labour Party and their loosely affiliated ‘Momentum’
You will recognise the pattern: A web page asks you to support a candidate. It usually gathers one or two small pieces of information (your postal code, whether you’re registered to vote, etc). From there, you receive regular emails asking for donations, you’re organised into a community of others where you may be asked to organise grassroots events, you may be encouraged to share particular messages on social media, you may be given little surveys that basically look like quizzes, but are intended to figure out which issues can be used to increase the likelihood of you voting for a candidate, or promoting a candidate, or – on the reverse – which issues could be used to prevent you from voting for the opposition.
Here’s how they explain what they do:

And here’s how they build profiles of supporters, also offering some matching up with social profiles:
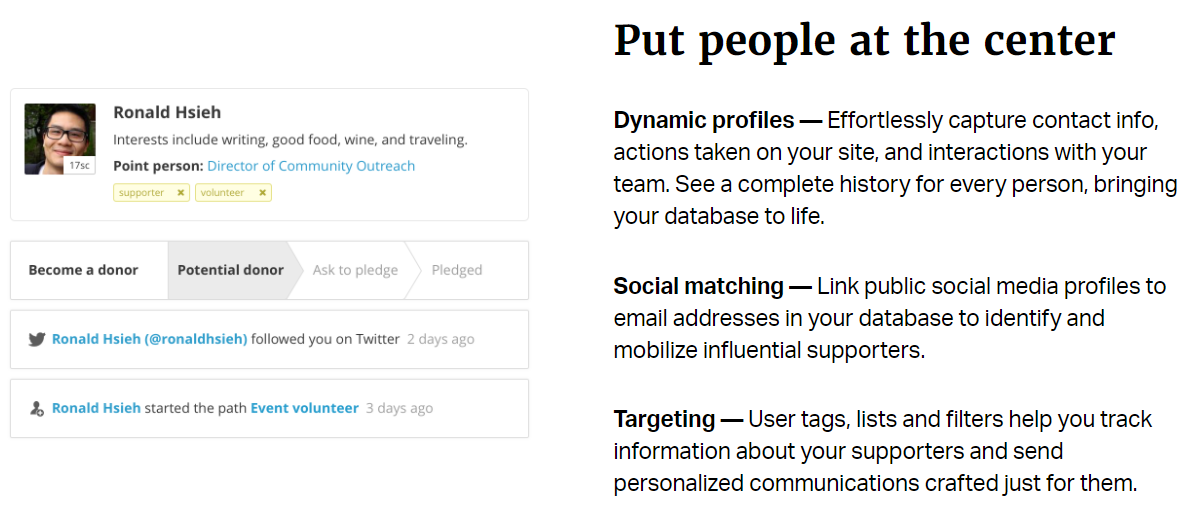
So there we have 3 pools of data, which we’ve joined together:
- A base of personality type data, which we can use to target particular types of ads/stories.
- A whole heap of behavioural data, showing which websites people visit, what they talk about on social media, etc.
- A lot of data we’ve gathered ourselves, all organised neatly in a way that allows us to identify supporters / advocates, gather donations, and push users to action.
Section B: Taking Action
We’ve discussed the data side of things; the other area Cambridge Analytica carried out services is in taking action on the basis of that data.
The actual actions Cambridge Analytica say they took, according to leaked presentations, is fairly basic. The data, and a process around adding to the data & understanding the current status of users, is the key part.
H犀利士
ere are 3 slides released by The Guardian, explaining what they did.
Action Tactic 1: Segmented / 1:1 targeting via email, social media.
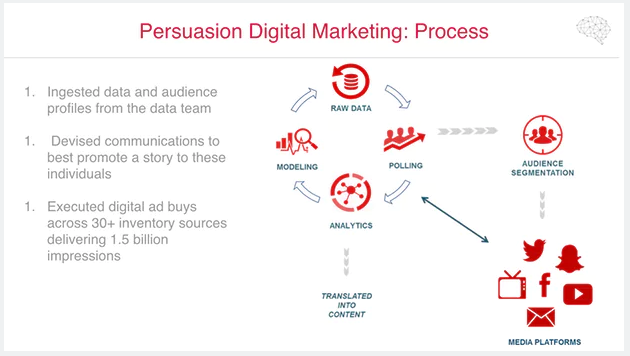
The above is essentially action based around the elements we’ve spoken about so far:
- Grow a large pool of data.
- Create ads (& other ‘content’) to target to particular groups or individuals within that pool. Show them those ads/pieces of content via Facebook, Youtube, Twitter, Snapchat, email, and also use for TV ads & messaging.
- Run polling to understand the current status of each user, or each segment (intent to vote, direction of vote, whether they’ve encouraged others/would encourage others, etc).
- Monitor the data.
- Understand whether you’re on target/off target with particular groups or particular regions, allowing you to prioritise.
- Alter ads/content on the basis of points 3, 4, 5 above.
That’s most of the 1:1 work, covered by social channels & email.
Action Tactic 2: Bigger Media Buys for Direct Action
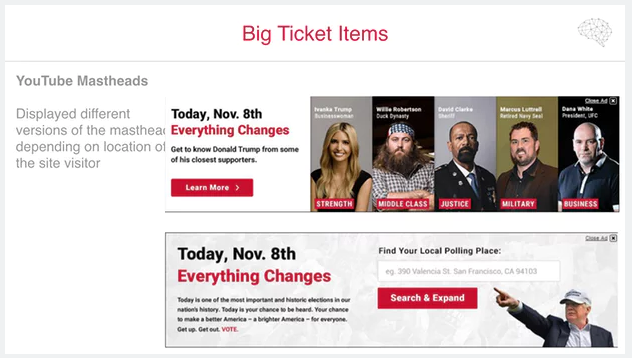
Here Cambridge Analytica say they placed ‘broader’ media buys. This is the type of activity that any very large consumer-facing campaign would carry out – buying mass ads to display to hundreds or millions of users. In their case, they say they targeted these in 3 ways:
- They based the messaging on elements they’d already measured as being successful within their more targeted advertising.
- They’d segmented these by location.
- They placed these on key outlets, where they knew they had a chance to affect behaviour, and placed them at crucial moments.
All three of the above are extremely straightforward if you’ve monitored your data closely through a campaign.
In terms of ‘crucial moments’: You can see the date on the above examples was election day itself: Ie, after all of the testing of ads prior, they ran a big push on election day itself. Everyone working in digital marketing will be familiar with the fact that the bulk of results for ‘direct response’ techniques (email, direct message campaigns, direct response ads) are immediately at the point that the money is spent, or the emails are sent. The ‘brand’ work to create users with the potential to act happens before that, the direct response activity is designed to have an impact at the point it goes live.
The above examples are also similar to the technique chosen by the official UK ‘Vote Leave’ Brexit campaign, who chose to spend large amounts of their media budget right at the end.

Action Tactic 3: Search Advertising
This is such a minor, simple detail compared to the other elements above, but Cambridge Analytica thought it worth setting out separately and showing off in presentations. That may be because it’s such a broad, simple tactic that it would appeal to any potential client without much awareness of digital advertising, or it may be that they actually felt it to be advanced.
Alongside all of the other tactics, they also explain they did something rather basic: Placed ads within Google search results, against particular terms users may search for. Here’s an example from their presentation:
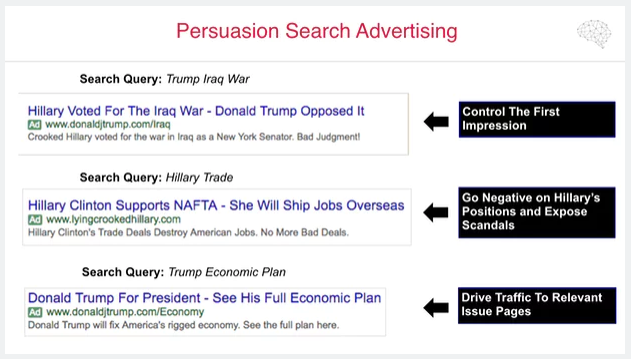
There are 3 ads there, that cover different elements of potential ‘voter journeys’:
- Ad 1: An ad that’s targeted at users searching for a particular factual topic. This is interesting in it positions him as opposing the Iraq war: Presumably that came back as a positive among the polling they did.
- Ad 2: A particularly negative ad re Hillary, related to a particular factual search. (user intent: which candidate am I aligned with re trade?)
- Ad 3: A positive ad re Donald Trump.
Each of the ads pointed to pages that set forward information, and also attempted to gather donations / email opt ins. This is vaguely interesting, but is particularly basic marketing that anyone working on a campaign with a decent amount of money would likely cover.
Overall Summary
What Cambridge Analytica appear to have done was not particularly advanced. It simply required money, people to carry out, and (it appears) the willingness of some to ignore their ‘ethical misalignments’ with the campaign.
All of the actual data/marketing techniques carried out were relatively straightforward, known tactics.
It’s no longer so easy to gather the data they did from the source they took it from, but there are plenty of other possibilities for gathering similar data sets – whether gathered directly in its entirety, partly gathered directly with additional data added to it from other sources, or bought in from either a fully legitimate source or a less legitimate source.