
When you visit BuzzFeed, they record lots of information about you.
Most websites record some information. BuzzFeed record a whole ton. I’ll start with the fairly mundane stuff, and then move on to one example of some slightly more scary stuff.
First: The Mundane Bits
Here’s a snapshot of what BuzzFeed records when you land on a page. They actually record much more than this, but this is just the info they pass to Google (stored within Google Analytics):
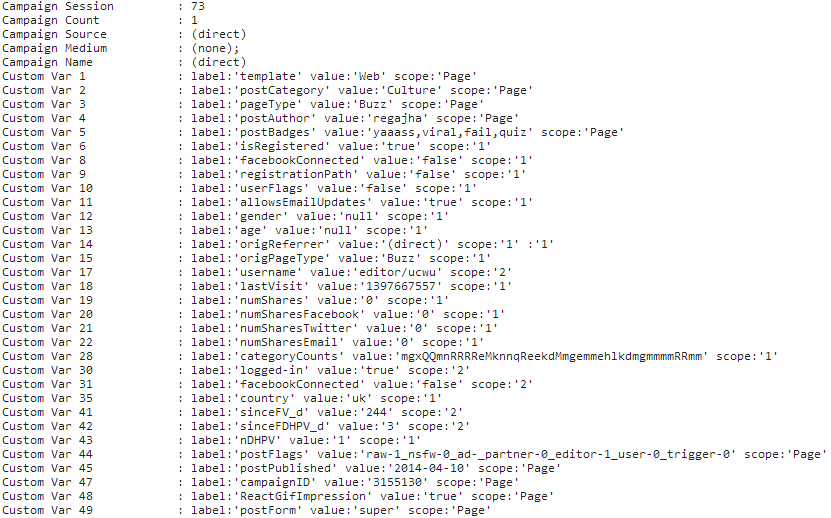
Here’s a description of what’s going on there:
The first line there is how many times in total I’ve visited the site (above this, which I’ve skipped for brevity, it also records the time I first visited, and a timestamp of my current visit).
Below that, the ‘Custom Var’ block is made up of elements BuzzFeed have actively decided “we need to record this in addition to what Google Analytics gives us out of the box”. Against these, you can see ‘scope’. A scope of ‘1’ means it’s something recorded about the user, ‘2’ means it’s recorded about the current visit, ‘page’ means it’s just a piece of information about the page itself.
There you can see other info they’re tracking, including:
- Have you connected Facebook with BuzzFeed?
- Do you have email updates enabled?
- Do they know your gender & age?
- How many times have you shared their content directly to Facebook & Twitter & via Email?
- Are you logged in?
- Which country are you in?
- Are you a buzzfeed editor?
- …and about 25 other pieces of information.
Within this you can also see it records ‘username’. I think that’s recording my user status, and an encoded version of my username. If I log in using 2 different browsers right now, it assigns me that same username string, but I’m going to caveat that I’m not 100% sure they’re recording that it is ‘me’ browsing the site (ie. that they’re able to link the data they’re recording in Google Analytics about my activity on the site back to my email address and other personally identifiable information). Either way, everything we’ve covered so far is quite mundane.
The Scary Bit
The scary bit occurs when you think about certain types of BuzzFeed content; most specifically: quizzes. Most quizzes are extremely benign – the stereotypical “Which [currently popular fictional TV show] Character Are You?” for example. But some of their quizzes are very specific, and very personal.
Here, for example, is a set of questions from a “How Privileged are You?” quiz, which has had 2,057,419 views at the time I write this. I’ve picked some of the questions that may cause you to think “actually, I wouldn’t necessarily want anyone recording my answers here”.

When you click any of those quiz answers, BuzzFeed record all of the mundane information we looked at earlier, plus they also records this:

Here’s what’s they’re recording there:
- ‘event’ simply means something happened that BuzzFeed chose to record in Google Analytics.
- ‘Buzz:content’ is how they’ve categorised the type of event.
- ‘clickab:quiz-answer’ means that the event was a quiz answer.
- ‘ad_unit_design3:desktopcontrol’ seems to be their definition of the design of the quiz answer that was clicked.
- ‘ol:1218987’ is the quiz ID. In other words, if they wish, they could say “show me all the data for quiz 1218987” knowing that’s the ‘Check Your Privelege’ quiz.
- ‘1219024’ is the actual answer I checked. Each quiz answer on BuzzFeed has a unique ID like this. Ie. if you click “I have never had an eating disorder” they record that click.
犀利士
In other words, if I had access to the BuzzFeed Google Analytics data, I could query data for people who got to the end of the quiz & indicated – by not checking that particular answer – that they have had an eating disorder. Or that they have tried to change their gender. Or I could run a query along the following lines if I wished:
- Show me all the data for anyone who answered the “Check Your Privelege” quiz but did not check “I have never taken medication for my mental health”.
In BuzzFeed’s defense, I’m sure when they set up the tracking in the first place they didn’t foresee that they’d be recording data from quizzes of this personal depth. This is just a single example, but I suspect this particular quiz would have had less than 2 million views if everyone completing it realised every click was being recorded & could potentially be reported on later – whether that data is fully identifiable back to individual users, or pseudonymous, or even totally anonymous.
What do you think?
I don’t blame BuzzFeed much. They’ll take what they can get.
But people do need to get smarter about how and where they share their data. This piece will help take the blinders off.
I blame BuzzFeed. F them and the horse they rode in on.
We should be more aware of our data leaks, but that doesn’t excuse Buzzf***.
Yup. I’m very tired of the argument that predatory websites are okay because you don’t have to use them. They’re not okay. They’re predatory. In my work with non-neurotypical people, I’ve seen them fall for internet scams again and again, while some jackwads mumble from the sidelines that everyone should just KNOW how to protect themselves online. Buzzfeed is a scam and there are no excuses for it.
A few thoughts, without a cohesive narrative…
– Logging the ‘scary’ stuff is pretty mundane in itself – that is, when collected anonymously and in aggregate. It’s only when combined with a ‘mundane’ unique identifier (username) that it crosses the creepy line.
– GA prohibits collection of personally identifiable information (PII). Passing a username may contravene rules (depending upon how it’s done).
– You give less information to get an insurance quote.
– In any other context there would be outrage that data like these are being collected over an insecure connection. They could easily be intercepted (PRISM/other Government surveillance, ISPs, industrial espionage, company Internet monitoring etc).
– Buzzfeed’s pretty open about data collected and what they do with them; they collect pretty much everything and will use it to sell targetted advertising (http://www.buzzfeed.com/about/privacy).
– Continuous scrolling means that a privacy policy link isn’t viewable on homepage
And now a slightly more cohesive conclusion…
We all leave digital footprints – Buzzfeed is an exaggerated example, but any data controller could present unique user profiles. Seemingly disparate data sets can be combined with relative ease.
Privacy is something to be traded. Free individuals should be able to determine the value (and price) of their personal data and trade accordingly. Those without full capacity to make decisions (e.g. children) need protection of law. Any contract (explicit or implicit) should be transparent.
Just read the privacy policy – it’s clear that they track everything, but how many people actually read the document?
Thanks for publishing this Dan!
David – some great points/thoughts you raise above as well. The one thing I did just want to clarify is that as far as I know (and IANAL) Google’s guidelines for GA I believe refer more to storing any PII on GA’s servers – or pushing any of that data to GA (https://support.google.com/analytics/answer/2795983?hl=en-GB).
I don’t believe that there is, in theory, any reason that you can’t use a customer ID that you use to stitch together data offline (at least from a GA rules perspective, laws governing data collection in some countries may well prohibit this as well).
At a guess I think Google is just trying to protect themselves here and want to be sure that they are not storing any PII that could get them into any trouble – and when you read cases like this you can totally understand why!
An interpretation of Google’s rules/guidelines is that a username can, in some circumstances, be PII. An email address or a name that the user has personally selected could fall into the PII category; [email protected] or jamessmith1998 would likely be classed this way.
There’s no problem using a unique, non-personal system-generated identifier – indeed, Universal Analytics itself relies on this.
The ‘safe’ way to pass a unique identifier is to use a random string stored in the CRM/DB.
(I’m afraid that I’m not a member of the digital carbuncle that is Buzzfeed, so can’t say what ‘username’ it passes!)
Good article – out of interest, what tool are you using to view the analytics request?
Thanks
Anyone know?
He’s probably using the Google Analytics debug extension (for Chrome). It allows you both to debug your analytics integration as it lets you see the data thats send to GA.
I think people should really start getting used to private/incognito browsing, and not logging into Facebook to do stuff around the internet, especially on BuzzFeed.
Hi Dan,
I run Growth and Data at BuzzFeed. I noticed that you added this caveat: “I’m going to caveat that I’m not 100% sure they’re recording that it is ‘me’ browsing the site (ie. that they’re able to link the data they’re recording in Google Analytics about my activity on the site back to my email address and other personally identifiable information). ”
This caveat is important because we do not in fact record that it is “you” browsing the site. The string sent to GA is not your username but an anonymized string that is not linked in any way to your account, email address or other personally identifiable information. Also, about 99% our readers are not even logged in.
We are only interested in data in the aggregate form. Who a specific user is and what he or she is doing on the site is actually a useless piece of information for us. We know how many people got Paris or prefer espresso in the Which city would you live in? quiz, but we don’t know who they are or any of their PII.
Theoretically, how hard would it be for someone at Buzzfeed to connect someone to their Buzzfeed quiz answers?
Thanks, Dao! That’s very much appreciated, and basically answers the question in the last line which is the data is ‘pseudonymous’ or ‘anonymous’.
The 99% number is really interesting & surprisingly high.
Here are 2 questions that may be useful. Feel free not to answer if they are too intrusive:
1. Why track an anonymised user-level string if you are not interested in user-level data? (How is the string created?)
2. As David noted above – might it be sensible to do something to block this data from being intercepted?
Thanks again,
dan
Hi Dao,
Two questions that I hope you wouldn’t mind answering for me:
1. If the “username” string is NOT associated with the individual’s account, then why is the same username string used for two different sessions?
The author found that the same string was sent when he logged in from two different browsers. These are two different user sessions, and the only things that they have in common are (a) the account that was logged into, and (b) the IP address of the computer in use. Both of these can be used to uniquely identify the person using the site. So, if the username string is not associated in any way with either of these pieces of information, how can it possibly be using the same string?
2. Can we interpret your final paragraph as meaning that none of your data analysis requires the username string in order to give you meaningful results? If “who a specific user is” is “useless” to you, then why bother including the username string in the GA data at all? If it’s useless, why not remove it? Contrariwise, if it is unremovable, for what use is it necessary?
Thanks!
-Andy
Another question for Dao – are non-sponsored quizzes ever created with the intention of attracting new sponsors? Does BuzzFeed seek out specific business or do all advertisers approach BuzzFeed?
Thanks!
You say the string is anonymized. How is this performed, technically? There are plenty of wrong ways to do it (eg., straight-up MD5 hash).
Good info Dan,
You should try going to healthcare.gov some time.
Cheers!
Bob
Hi Dan,
Thank you for your post, which appeared on my Facebook wall about an hour ago.
It’s funny because you’re pointing at something I’ve been struggling with for a couple of weeks now: could sensitive content be part of a Privacy debate?
So the fact that the person is identifiable or not, is indeed usually the initial question but let me start with the beginning.
I opened Buzzfeed on my iPad and it suggested their app. to be honest, I have no idea what Buzzfeed is so I’m discovering. The app has no Privacy Policy, unlike for example the Onion. Their copyright on the app dates back to 2010 so I imagine that in terms of Privacy policies or any legal matter related to what they are collecting, it must be rather “light” to say it politely.
I then went to their user agreement on my desktop, which you can find here: http://www.buzzfeed.com/about/useragreement. It’s interesting to note for example that they mention you should be over 18 to use the website. It reminded me of websites promoting alcohol. Don’t you usually get some kind of trigger to state your birthdate to make sure you’re over 18? I mean, you can always lie of course but at least, there is some affirmative action to take to make sure you understand the terms like http://www.disaronno.com/.
Here, you have to catch their User Agreement when scrolling down and actually read through it. How many of us do that actually? 2-5% are the figures I’ve been seeing…
There are other bits and pieces in this user agreement which are of interest. The ones is capital letters usually are very interesting to decipher from a legal perspective. And one should also note that the governing law is the state of NY. In light of the upcoming European Personal Data Protection Regulation, it will be interesting to see how this will affect this particular stance. Indeed, as their User Agreement is also available in French (as I mentioned, I’m not familiar with Buzzfeed but it does make me wonder), I imagine they must have a substantial French client base?
Getting back to the non identifiability of an individual, which is indeed against Google Analytics’ terms of use, there are about a dozen trackers on there.
So, this being an american site, and in light of the recent Data Brokers report of the FTC (http://www.ftc.gov/system/files/documents/reports/data-brokers-call-transparency-accountability-report-federal-trade-commission-may-2014/140527databrokerreport.pdf), it’s no stretch of the imagination to think that data collected here could be shared, sold?, with/to a third party.
We could decrypt their Privacy Policy for that http://www.buzzfeed.com/about/privacy but it would mainly mean taking a closer look at their exact data flows.
Getting back to the sensitive type of information issue. I stumbled upon the question when analysing terms and conditions of the analytics tools we all use: GA/GAP, Adobe & then IBM. They have a range of tolerance let’s say: Google typically doesn’t want to come near anything that could identify an individual so storing email addresses, which is considered PII in all US states is agains their Terms. Enforcement, now that’s another issue entirely. Adobe doesn’t like “sensitive” data and IBM is all fine and well as long as you abide by the laws of the land.
Sensitive data is usually linked to financial, health, sexual preferences, political preferences, etc. and in the US, sector related legislation only quicks in if and only if you’re collecting… PII. The same can not be said for (continental) Europe.
It might be worth while to at least clean up the app policy for Buzzfeed if this is still useful from a business perspective, just to avoid the potential backlash of a negative image.
There’s clearly a lot in what they are doing what makes me feel uncomfortable and I would have suggestions to improve their ways of working. But I’m European and a reformed analyst that likes to challenge Privacy set-ups 😉
I do wonder if they could have been picked up by the 2nd global Privacy sweep, which this time around focused on apps https://www.priv.gc.ca/media/nr-c/2014/nr-c_140506_e.asp. Let’s see: the report comes out in the fall but I suppose not, hopefully Buzzfeed got lucky. They should take advantage of that…
Aurélie
Is it just me that’s thinking ‘great, I can now target people that [insert attribute] with my [insert product]’. Even if anonymised, which I’m sure it is, this gives Buzzfeed the ability to personalise content for users in a very specific way, according to very specific attributes, ie a dieting post to users who have eating disorders They appear to know far more than any data aggregator I know. Dan, great spot as usual..
I would need to see what they do about ID tracking and whether that maps to a specific user identity and name, but generally speaking, the data gathered by any entity that tracks this stuff is anonymized out of the gate for one simple reason: it’s in their best interest.
Think of tracked data as a gigantic, abstract spreadsheet with hundreds of thousands, or even millions, of rows (these represent individual users) and hundreds of columns (these represent data metrics: birth date, sexual orientation, gender identity, political preferences, medical history, etc.). The amount of data that flows across busy platforms for just one such huge spreadsheet can be in the terabytes. In other words, enough that storing data for more than a very limited period of time, or even adding an additional column for which each row will need to have data in the short term, is enough to slow or crash servers on a pretty massive scale. As a result most companies that do gather user data wipe their servers completely of this data at the 30-day mark, and after that it is not available to anyone. It simply does not exist. So even those companies that could, theoretically, profit from storing data that maps user behavior/anonymized ID numbers to actual real people with names and social security numbers, unless they are really in league with, say, the NSA and their purpose is to aggressively spy on their users, it would generally not be worth the investment in server capacity. I’m not saying it couldn’t happen (don’t get me wrong, I absolutely do believe if a motivated government body or 4chan type got a bee in their bonnet, this is very possible). But in general there is not a huge amount of motive around this kind of tracking, because except in really specific cases it’s an enormous amount of overhead for very little payoff, and the amount of planning ahead and server capacity that would need to be earmarked to *potentially someday* be in league with an evil data-user is just not worth it. Also, clearing your browser cache and cookies, and not clicking through to stuff from Facebook — which does do more user tracking mapped to names and identities for marketing behaviors purposes — is enough to wipe a lot of the trace-able data to the point it can’t harm you.
To give you some background, I work in ad tech currently, after 12+ years working in socially conscious nonprofits, and when I took my current job I did a lot of research to make sure I was working for a place whose data privacy ethics I respected and could get behind. I’m a tech writer responsible for client-facing documentation, and I work closely with people on legal and policy teams to articulate the extent to which we do NOT do this kind of stuff or even support such tracking by users of our platform — it’s been comforting to have an active role in that, and also very eye-opening to discover how much of the malice most assume goes into data logging and tracking is based on poor understandings of what it means to gather and store data on a massive scale. Super important to note that this kind of data can be collected and call for accountability, as you are doing here, but equally important to diffuse paranoia about data collection that’s based on inaccurate understanding of motive and collateral for the entities that do this stuff.
Also, a word on the value: the thing that is valuable about user profiles is the behaviors (reads X, buys Y, lives in place Z) but once you have that a name or address is irrelevant. Sites like Buzzfeed make tons and tons of money off of ad impressions (which are tailored to specific users’ behaviors) and sponsored content (which is tailored to more general data about who uses their site longitudinally), but targeting behaviors and preferences is really different from targeting individual people. You can sell a pair of high-end shoes to, say, a new parent who is eco-conscious, gay, and has a bad knee and is living in the greater Albany area and at no point do you benefit from knowing that person’s name and address. As you get more granular in your ad targeting, the users become more “valuable” until about the city level, at which point the value of specific targeting drops way down because of the ROI (back to the spreadsheet concept again: data volume vs. actual value of those targeted in terms of buying power * number of individuals).
hi, Diana! Thanks for the very comprehensive comment. I agree with most of it, but the part about it being in a company’s best interest to anonymise purely from the point of view of data storage isn’t quite right: It takes no additional space to store a user ID that can be linked back to personally identifiable information than it does pseudonymised. Lots of companies track actual user data, and store if for much longer than 30 days. As an ultra-simplistic example, your utilities companies probably do this (often along with a heap of information about your utility usage). As an even more simplistic example – the comment that you left here is, of course, stored within a database on a server somewhere, along with your email address & IP address.
On your point about wiping cookies, etc, take a look here & hit the ‘test’ button: https://panopticlick.eff.org/
Bit of a minefield, eh?
If I were an unscrupulous organisation of some kind, surely I could use this knowledge to identify an individual for my own ends regardless of whether or not it’s anonymous at the Buzzfeed end? E.g. let’s say I run an ad for medical insurance. If I stick a campaign code on it I can track who comes to my site from that ad. But what if I decide to run two ads, identical except for the campaign codes I use, targeting one at the people who didn’t declare any mental health issues in that Buzzfeed quiz, and another at those who did. If anyone comes to my site via my ad, I now know what segment they fall into and can apply that information to any account they sign up to on my site, maybe only offering my best discount to those who declared no issues. And I wouldn’t even need to do this targeting based on ‘relevant’ segments… I’m hoping there’s some kind of legal protection against this, but I don’t know…
if Buzzfeed is going to invade my privacy and create data they believe describes me, the least they could do is tell me how I scored on that!! Do I need to run to the mental health peeps or am I normally abnormal? ?